IPAがやっている、IPA文字情報基盤というのがある。
そこで出しているフォントがIPAmj明朝。
結構前からやってたと思うのですが、そろそろ各自治体での利用が
広がりそうなのでちょっとまとめ。マイナンバーのフォントはこれ使ってるらしい。
ほんとかどうかは不明。
前に国が似たようなブラウザ表示の確認をやってて、報告書みたいなのがネットに転がってたと思うのですが、相当古かったと思うので今の時点だとどうかというところ。
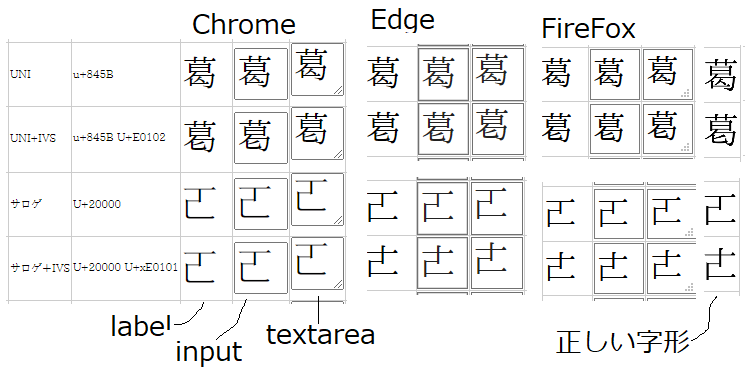
日本語で気を付けないといけないのは、通常のUniの文字以外に、
UNI+IVS、サロゲ、サロゲ+IVSあたりがある。※あとは外字。
IPAmj明朝はそういうところもやってるので、表示が出来るかどうかというところ。
とりあえず、Chrome・Edge・Firefoxの結果。
使った各ブラウザのバージョンは下記。
Chrome 86.0.4240.183(Official Build) (64 ビット) FireFox 82.0.2 (64 ビット) Edge Microsoft Edge 42.17134.1098.0 Microsoft EdgeHTML 17.17134 OSはWindows10
フォント指定のCSS
.ipafont {
font-family: 'IPAmjMincho', 'IPAmj明朝';
}
実HTML置いておくので、自環境で確認したい場合はご利用ください。※クライアントにIPAmj明朝インストールしないとまともに表示されません。
| パターン | CODE | 字(HTML) | input | textarea | 正解画像 |
|---|---|---|---|---|---|
| UNI | u+845B | 葛 |  |
||
| UNI+IVS | u+845B U+E0102 | 葛󠄂 |  |
||
| サロゲ | U+20000 | 𠀀 |  |
||
| サロゲ+IVS | U+20000 U+xE0101 | 𠀀󠄁 |  |
UNIとUNI+IVSはどのブラウザも問題無し。
問題はサロゲ。EdgeとFireFoxはOK。ChromeはIPAフォント使えてない...
Chromeさんバグってます?
あと、inputのmaxlength。
Edgeだけはどのパターンの文字も一文字としてカウントしてくれてる。
FireFoxとChromeさんは例えば、maxlength="4"って指定しても、サロゲ+IVSなんかだと、1文字しか入力できなくなる。
日本語の文字・フォントの扱いは「Edge > |超えられない壁| > FireFox > Chrome」って感じかしら。
Edgeがだいぶ優秀ですね。
つか、日本語みたいな少数民族の文字なんて英語圏の開発者からみたら正直どうでもいいでしょうしね。しょうがないと言えばしょうがない...
inputのmaxlengthは自前で作らないとダメそう。
chromeさんの表示がダメなのは治るのを期待して気長に待つしかないかな?
と思ったけど、別環境のchromeで見るとちゃんと表示されてる...
ん?何か違うか?謎。要確認。
追記
Chrome、複数環境で何個か確認したけど、やっぱりちゃんと表示されていた(Linux含む。
最初に確認した環境のみおかしいっぽい。Chromeさん濡れ衣でした。スミマセン。
でも何で最初の環境はおかしいんだろうか?EdgeとかFireFoxは大丈夫なんだけども...
あと、以下のIPAが出してる文字一覧でひそかに謎の定義が存在する。

”ここだけ”IVS定義が重複して存在するという...
ホントこういうのは止めて欲しいところ。何か理由があるのでしょうけども。
2021/1/2追記
自治体システム標準化でこのフォントが標準になっていくと思うのですが、Webで扱うにはデカ過ぎるんですよね。本体30MBくらいあったと思う。これWebフォントにしろとか言わないよね...
標準化するならクライアントにこのフォントをインストールする前提で考えさせてほしいところ。
昔に比べたら十分早くはなっていると思うのですが、全面Webフォントとかクソ重くなりそう...
業務システム的に考えると、結局CSVとかエクセルとか落として、事務的な計算とかをやるので、そっちでフォント使えないと結局アレですし。ローカルインストール前提にして欲しいよね。
まーでも、人名や住所で外字がなくなるとは思えないので、IPAmj明朝にする意味がどこまであるのやら。。。
標準システムで、本気で外字の利用をNGにしてくれるんならいいんだけどなー。まー無理そう。国としてオープンデータの流れに持っていきたいのであれば、この辺の基礎的な部分はガチガチに固めてくれてもいいと思うんだけど。
SEの端くれ的な感覚で、エンジニア側の都合だけで考えれば統一してよって感じではある。何もしないで標準で動くのが一番良い。というか楽。
ただ、やっぱり自分の名前や文字っていうのは一つの文化なわけで、そこのこだわりを捨てろっていうのも暴論な気もするし難しいところですね。
全国で文字の字形の同定を行って外字に入ってる文字の統一は、作業的には出来なくはない(恐ろしく手間かかるし、泥臭い作業になりますが。。。
ただ、それをやった場合に、既存データの置き換えを自治体毎に置換のPG組まないとダメそうだし、データ移行な作業もとんでもないコストかかりそうだし、やっぱりなかなか難しそうですね。。。

IVSの重複の件、元々はU+535Aの異体字扱いだったがU+289E4がUnicodeに追加されそちらに変更したのでしょう。なのでU+535Aの方は後方互換というか。単に重複がイヤならU+289E4の方だけ使えばいいかと。U+289E4が使える環境では。
Unicodeにどう文字が入るかはIPAが管理しているわけではないですし、かといって無視はできない、的な?